Inside OpenAI’s in-house data agent
TL;DR
OpenAI built an internal AI data agent to help employees quickly access and analyze data using natural language. It uses GPT-5.2 and other OpenAI tools to reason over data, self-learn, and reduce analysis time from days to minutes.
Key Takeaways
- •OpenAI's custom AI data agent enables employees to get data insights in minutes through natural language queries, improving efficiency across teams.
- •The agent uses GPT-5.2 and integrates with tools like Codex and the Embeddings API to handle complex data analysis and self-correct errors.
- •It addresses challenges in OpenAI's large data platform, such as finding the right tables and avoiding SQL errors, freeing analysts for higher-level tasks.
Tags
Data powers how systems learn, products evolve, and how companies make choices. But getting answers quickly, correctly, and with the right context is often harder than it should be. To make this easier as OpenAI scales, we built our own bespoke in-house AI data agent that explores and reasons over our own platform.
Our agent is a custom internal-only tool (not an external offering), built specifically around OpenAI’s data, permissions, and workflows. We’re showing how we built and use it to help surface examples of the real, impactful ways AI can support day-to-day work across our teams. The OpenAI tools we used to build and run it (Codex, our GPT‑5 flagship model, the Evals API(opens in a new window), and the Embeddings API(opens in a new window)) are the same tools we make available to developers everywhere.
Our data agent lets employees go from question to insight in minutes, not days. This lowers the bar to pulling data and nuanced analysis across all functions, not just by our data team. Today, teams across Engineering, Data Science, Go-To-Market, Finance, and Research at OpenAI lean on the agent to answer high-impact data questions. For example, it can help answer how to evaluate launches and understand business health, all through the intuitive format of natural language. The agent combines Codex-powered table-level knowledge with product and organizational context. Its continuously learning memory system means it also improves with every turn.

In this post, we’ll break down why we needed a bespoke AI data agent, what makes its code-enriched data context and self-learning so useful, and lessons we learned along the way.
Why we needed a custom tool
OpenAI’s data platform serves more than 3.5k internal users working across Engineering, Product, and Research, spanning over 600 petabytes of data across 70k datasets. At that size, simply finding the right table can be one of the most time-consuming parts of doing analysis.
As one internal user put it:
“We have a lot of tables that are fairly similar, and I spend tons of time trying to figure out how they’re different and which to use. Some include logged-out users, some don’t. Some have overlapping fields; it’s hard to tell what is what.”
Even with the correct tables selected, producing correct results can be challenging. Analysts must reason about table data and table relationships to ensure transformations and filters are applied correctly. Common failure modes—many-to-many joins, filter pushdown errors, and unhandled nulls—can silently invalidate results. At OpenAI’s scale, analysts should not have to sink time into debugging SQL semantics or query performance: their focus should be on defining metrics, validating assumptions, and making data-driven decisions.

This SQL statement is 180+ lines long. It’s not easy to know if we’re joining the right tables and querying the right columns.
How it works
Let’s walk through what our agent is, how it curates context, and how it keeps self-improving.
Our agent is powered by GPT‑5.2 and is designed to reason over OpenAI’s data platform. It’s available wherever employees already work: as a Slack agent, through a web interface, inside IDEs, in the Codex CLI via MCP(opens in a new window), and directly in OpenAI’s internal ChatGPT app through a MCP connector(opens in a new window).

Users can ask complex, open-ended questions which would typically require multiple rounds of manual exploration. Take this example prompt, which uses a test data set: “For NYC taxi trips, which pickup-to-dropoff ZIP pairs are the most unreliable, with the largest gap between typical and worst-case travel times, and when does that variability occur?”
The agent handles the analysis end-to-end, from understanding the question to exploring the data, running queries, and synthesizing findings.
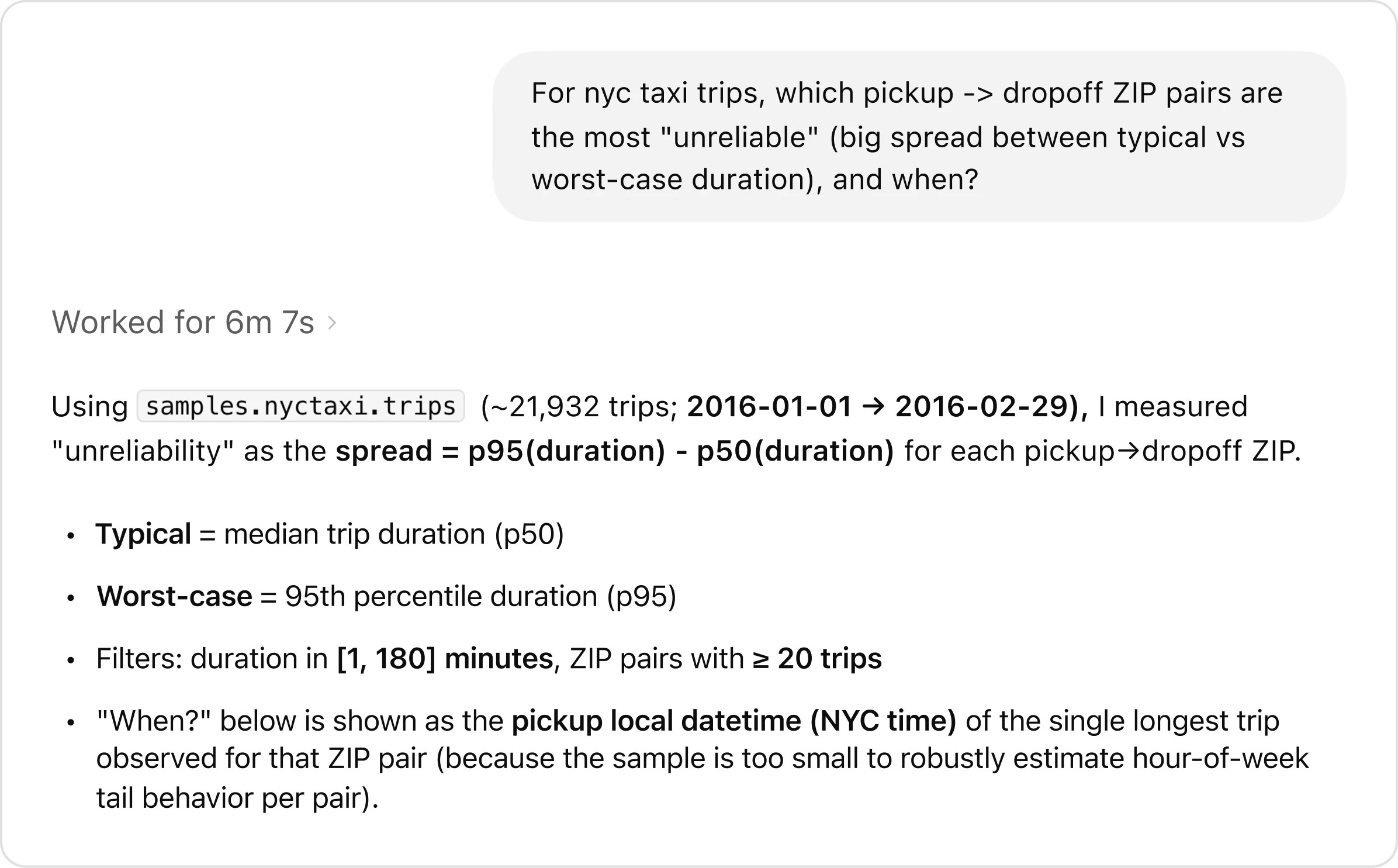
The agent's response to the question.
One of the agent’s superpowers is how it reasons through problems. Rather than following a fixed script, the agent evaluates its own progress. If an intermediate result looks wrong (e.g., if it has zero rows due to an incorrect join or filter), the agent investigates what went wrong, adjusts its approach, and tries again. Throughout this process, it retains full context, and carries learnings forward between steps. This closed-loop, self-learning process shifts iteration from the user into the agent itself, enabling faster results and consistently higher-quality analyses than manual workflows.