Netomi’s lessons for scaling agentic systems into the enterprise
TL;DR
Netomi's enterprise AI agent platform combines GPT-4.1 for fast tool use and GPT-5.2 for multi-step planning within a governed execution layer. Key lessons include designing for real-world complexity, parallelizing for low latency, and embedding governance directly into runtime operations.
Key Takeaways
- •Build for real-world complexity by orchestrating multiple systems and handling ambiguous data, using GPT-4.1 for reliable tool-calling and GPT-5.2 for deeper planning.
- •Parallelize operations to meet enterprise latency expectations, leveraging GPT-4.1's low-latency streaming and stable tool-calling to handle high concurrent requests.
- •Integrate governance intrinsically into the runtime with schema validation, policy enforcement, PII protection, and deterministic fallback to ensure trustworthy AI behavior.
- •Use agentic prompting patterns like persistence reminders and structured planning to maintain state across multi-step workflows and prevent hallucinated responses.
- •Scale across demanding industries by combining OpenAI models with systems engineering for operational safety, auditability, and Fortune 500 readiness.
Tags
Enterprises expect AI agents to handle messy workflows reliably, honor policies by default, operate under heavy load, and show their work.
Netomi(opens in a new window) builds systems that meet that high bar, serving Fortune 500 customers like United Airlines and DraftKings. Their platform pairs GPT‑4.1 for low-latency, reliable tool use with GPT‑5.2 for deeper, multi-step planning, running both inside a governed execution layer designed to keep model-driven actions predictable under real production conditions.
Running agentic systems at this scale has given Netomi a blueprint for what makes these deployments work inside the enterprise.
Lesson 1: Build for real-world complexity, not idealized flows
A single enterprise request rarely maps to a single API. Real workflows span booking engines, loyalty databases, CRM systems, policy logic, payments, and knowledge sources. The data is often incomplete, conflicting, or time-sensitive. Systems that depend on brittle flows collapse under this variability.
Netomi designed its Agentic OS so OpenAI models sit at the center of a governed orchestration pipeline built for this level of ambiguity. The platform uses GPT‑4.1 for fast, reliable reasoning and tool-calling—critical for real-time workflows—and GPT‑5.2 when multi-step planning or deeper reasoning is required.
“Our goal was to orchestrate the many systems a human agent would normally juggle and do it safely at machine speed.”
To ensure consistent agent behavior across long, complex tasks, Netomi follows the agentic prompting patterns recommended by OpenAI:
- Persistence reminders to help GPT‑5.2 carry reasoning across long, multi-step workflows
- Explicit tool-use expectations, suppressing hallucinated answers by steering GPT‑4.1 to call tools for authoritative information during transactional operations
- Structured planning, which leverages GPT‑5.2’s deeper reasoning to outline and execute multi-step tasks
- Agent-driven rich media decisions, relying on GPT‑5.2 to detect and signal when a tool call should return images, videos, forms, or other rich, multimodal elements
Together, these patterns help the model reliably map unstructured requests to multi-step workflows and maintain state across discontinuous interactions.
Few industries expose the need for multi-step reasoning as clearly as airlines, where one interaction routinely spans multiple systems and policy layers. A single question may require checking fare rules, recalculating loyalty benefits, initiating ticket changes, and coordinating with flight operations.
“In airlines, context changes by the minute. AI has to reason about the scene the customer is in—not just execute a siloed task,” said Mehta. “That’s why situational awareness matters way more than just workflows, and why a context-led ensemble architecture is essential.”
With GPT‑4.1 and GPT‑5.2, Netomi can keep extending these patterns into richer multi-step automations—using the models not just to answer questions, but to plan tasks, sequence actions, and coordinate the backend systems a major airline depends on.
Lesson 2: Parallelize everything to meet enterprise latency expectations
In high-pressure moments—rebooking during a storm, resolving a billing issue, or handling sudden spikes in demand—users will abandon any system that hesitates. Latency defines trust.
Most AI systems fail because they execute tasks sequentially: classify → retrieve → validate → call tools → generate output. Netomi instead designed for concurrency, taking advantage of low-latency streaming and tool-calling stability of GPT‑4.1.
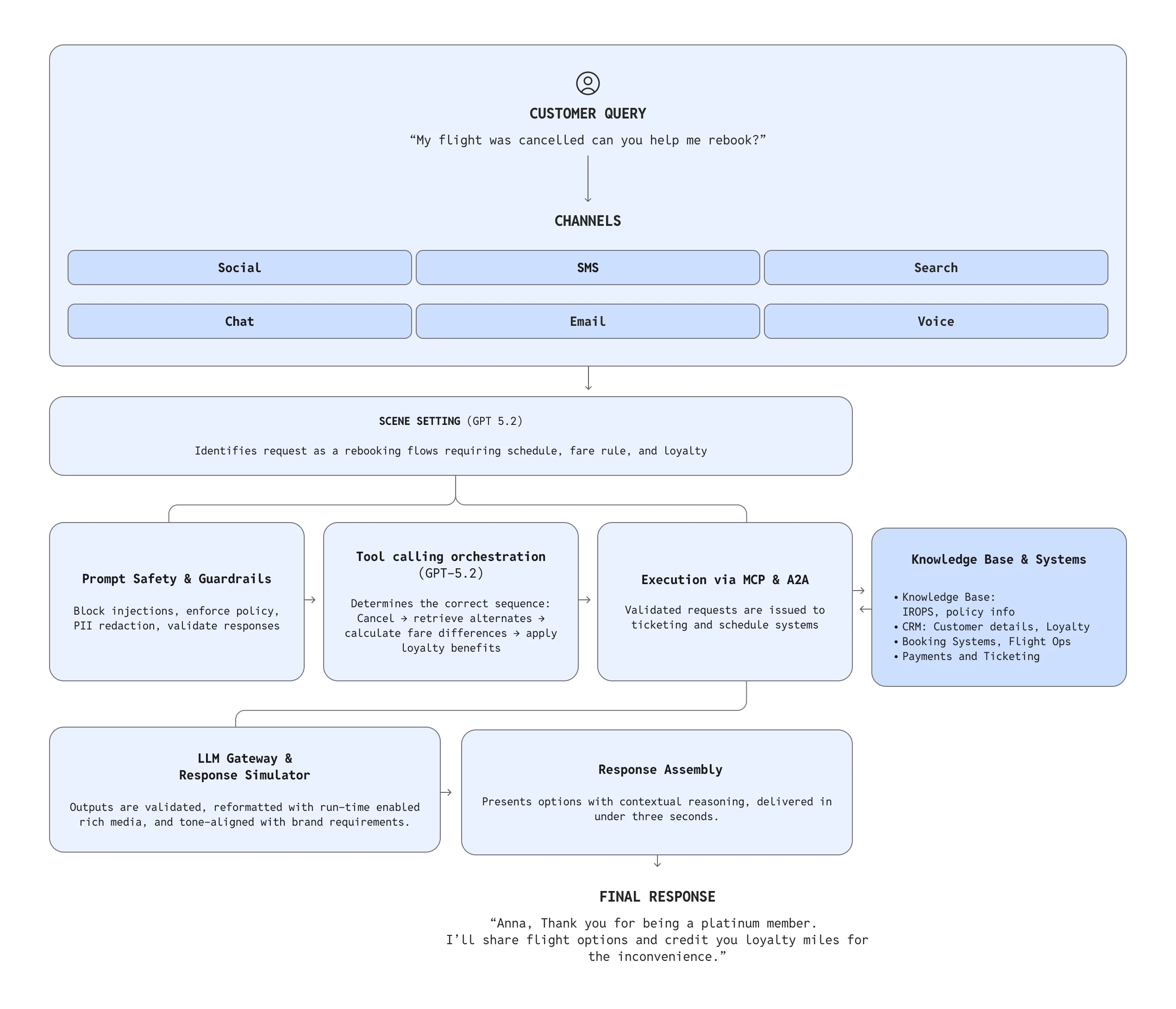
GPT‑4.1 provides fast time-to-first-token and predictable tool-calling behavior, which make this architecture viable at scale; while GPT‑5.2 provides deeper multi-step reasoning paths when needed. Netomi’s concurrency framework ensures the total system, not just the model, stays under critical latency thresholds.
These concurrency demands aren’t unique to airlines. Any system exposed to sudden, extreme traffic surges needs the same architectural discipline. DraftKings, for instance, regularly stress-tests this model, with traffic during major sporting events spiking above 40,000 concurrent customer requests per second.
During such events, Netomi has sustained sub-three-second responses with 98% intent classification accuracy, even as workflows touch accounts, payments, knowledge lookups, and regulatory checks.
“AI is central and critical to how we support customers in the moments that matter most,” said Paul Liberman, Co-Founder and President of Operations at DraftKings. “Netomi’s platform helps us handle massive spikes in activity with agility and precision.”
At scale, Netomi’s concurrency model depends on the fast, predictable tool-calling of GPT‑4.1, which keeps multi-step workflows responsive under extreme load.
Lesson 3: Make governance an intrinsic part of the runtime
Enterprise AI must be trustworthy by design, with governance woven directly into the runtime—not added as an external layer.
When intent confidence drops below threshold, or when a request cannot be classified with high certainty, Netomi’s governance mechanisms kick in to determine how the request is handled, ensuring the system backs off from free-form generation in favor of controlled execution paths.
At a technical level, the governance layer handles:
- Schema validation, which validates every tool call against expected arguments and OpenAPI contracts before execution
- Policy enforcement that applies topic filters, brand restrictions, and compliance checks inline during reasoning and tool use
- PII protection to detect and mask sensitive data as part of pre-processing and response handling
- Deterministic fallback, routing back to known-safe behaviors when intent, data, or tool calls are ambiguous
- Runtime observability, exposing token traces, reasoning steps, and tool-chain logs for real-time inspection and debugging
In highly regulated domains like dental insurance, this kind of governance is non-negotiable. A Netomi customer in the insurance industry processes close to two million provider requests each year across all 50 states, including eligibility checks, benefits lookups, and claim status inquiries where a single incorrect response can create downstream regulatory or service risk.
During open enrollment, when scrutiny and volume peaked, the company needed AI that enforced policy as part of the runtime itself. Netomi’s architecture was up to that complex requirement.
“We built the system so that if the agent ever reaches uncertainty, it knows exactly how to back off safely,” said Mehta. “The governance is not bolted on—it’s part of the runtime.”
A blueprint for building agentic systems that work for the enterprise
Netomi’s path shows what it takes to earn enterprise trust: build for complexity, parallelize to meet latency demands, and bake governance into every workflow. OpenAI models form the reasoning backbone, while Netomi’s systems engineering ensures that intelligence is operationally safe, auditable, and ready for Fortune 500 environments.
These principles helped Netomi scale across some of the world’s most demanding industries—and offer a blueprint for any startup looking to turn agentic AI into production-grade infrastructure.