Mapping the neuronal building blocks of human language with language models
Abstract
Humans can convey new and highly diverse information through language. This ability to form and combine words into elaborate phrases and sentences enables us to express inexhaustible meanings and is fundamental to human cognition1,2,3,4,5. However, understanding the microscopic cellular building blocks and cortical landscape that precisely underlie human language has remained a challenge. Here we used wide-scale single-neuronal recordings combined with natural language processing models to identify fine-grained linguistic representations across the human frontotemporal cortex during language production. We find that, whereas certain neurons represented the detailed grammatical relationships between words or their parts of speech, others tracked the sentences’ higher-order syntactic structure, their phrase transitions and sequence. Collectively, these neurons reliably captured the words’ syntactic and semantic properties but also dynamically incorporated their specific sentence contexts, therefore enabling them to encode information combinatorially and at highly granular levels of detail. We show how these cell populations were locally organized and how their microscale representations differed from that of their wider field potential patterns. We also show how these neurons were distributed broadly across the frontotemporal cortex, but how their ability to encode linguistic information was left-lateralized and varied between cortical regions. Together, these findings identify some of the most basic cellular building blocks by which linguistic information is encoded in humans and begin to define the cortical landscape of language at a combined micro (cellular), meso (local population) and macro (regional) scale.
Main
Language is a fundamental cognitive process unique to humans that allows us to communicate complex and highly diverse meanings. It also enables us to construct new and potentially inexhaustible expressions through grammatical rules that govern how we arrange and combine words and that can generalize across sentences beyond simple repetition. Linguistic studies based on behavioural observations have accurately described how we use the properties of words, such as their grammatical function and syntactic relationships, to construct unique sentences1,2,3. They have also described how we use the hierarchical structure of phrases and sentences to communicate specific ideas and thoughts6. Recent neuroimaging7,8,9,10,11 and electrocorticographic recordings5,12,13,14,15, in turn, have identified broadly distributed regions across the frontotemporal cortex that reliably engage in speech production and sentence construction16,17,18,19 and that differentiate grammatically well-formed sentences from unstructured word lists or sounds, suggesting their sensitivity to syntactic structure20,21. They have also found neural responses that reflect the merger of words into phrases6 and their semantic properties22,23, revealing a broad macroscopic network of cortical areas that could support human language.
However, understanding the microscopic organization and cortical landscape by which linguistic information is encoded by neurons in humans or the cellular processes that underlie natural speech has remained a longstanding challenge. While recent investigations have revealed how the phonetic components of words are encoded by neurons24,25, they do not reveal the cellular processes by which we produce meaningful speech or through which we arrange and combine words into phrases and sentences. To convey meaning through language, for example, humans use abstract grammatical categories (such as adjectives and nouns) and dependencies (such as the relationship between nominal subjects and objects) that can generalize across sentences and that can describe complex relationships such as actions and outcomes. Yet, how such grammatical features are encoded by neurons or whether they generalize across sentences largely remains undefined. Little is also known about whether neurons can represent the higher-order syntactic structure of sentences or how they encode their constituent phrases.
Another prominent question in neurolinguistics is whether syntactic information is dissociable to some degree from that of semantic information, or how these core aspects of language are represented at a cellular scale26,27. Whereas previous imaging studies have suggested that linguistic information is probably represented broadly across the brain28,29, little is also known about how such information is distributed across cortical regions or whether speech processes are lateralized at a basic cellular level. Finally, little is known about how the local activities of individual neurons and their tuning properties relate to those of the populations’ broader field potential patterns, or what their local organization within the cortex may be.
Here we performed single-neuronal recordings across the human frontotemporal cortex and tracked their action potential (AP) and local field potential (LFP) activities over long-term durations as participants produced natural speech. Using speech tracking, parsing, modelling and decoding techniques, we describe the detailed organization and encoding properties of the neurons. We also describe their distribution, regionality and lateralization, together providing a detailed examination of linguistic information encoding during language production at a combined micro (cellular), meso (local population) and macro (regional) scale.
Recording neurons during natural speech
Recordings were obtained from neurons across the human frontotemporal cortex using semichronically implanted microelectrode arrays (96 channel configuration)30,31,32. These arrays were implanted as part of planned neurosurgical care for epilepsy monitoring30,33,34 and were located in the frontal35,36, anterior temporal20,37 and posterior temporal38,39,40 regions that have been shown to reliably engage in speech production and sentence construction41,42,43 and to display robust language-selective responses41,42,44 by validated language localizers28,41,45 (Fig. 1a). They were also placed in participants who were awake, after implantation, and were therefore capable of producing natural speech, together providing a rare opportunity to study the activities of individual neurons during natural language production (see the ‘Microelectrode recordings’ section of the Methods). In total, we recorded from 579 putative neurons in 8 participants (3 female, 5 male, aged 27 to 52 years) and 14 sessions and only well-isolated single units with stable waveform morphologies consistent with those of cortical neurons were used (Fig. 1b and Extended Data Fig. 1a).
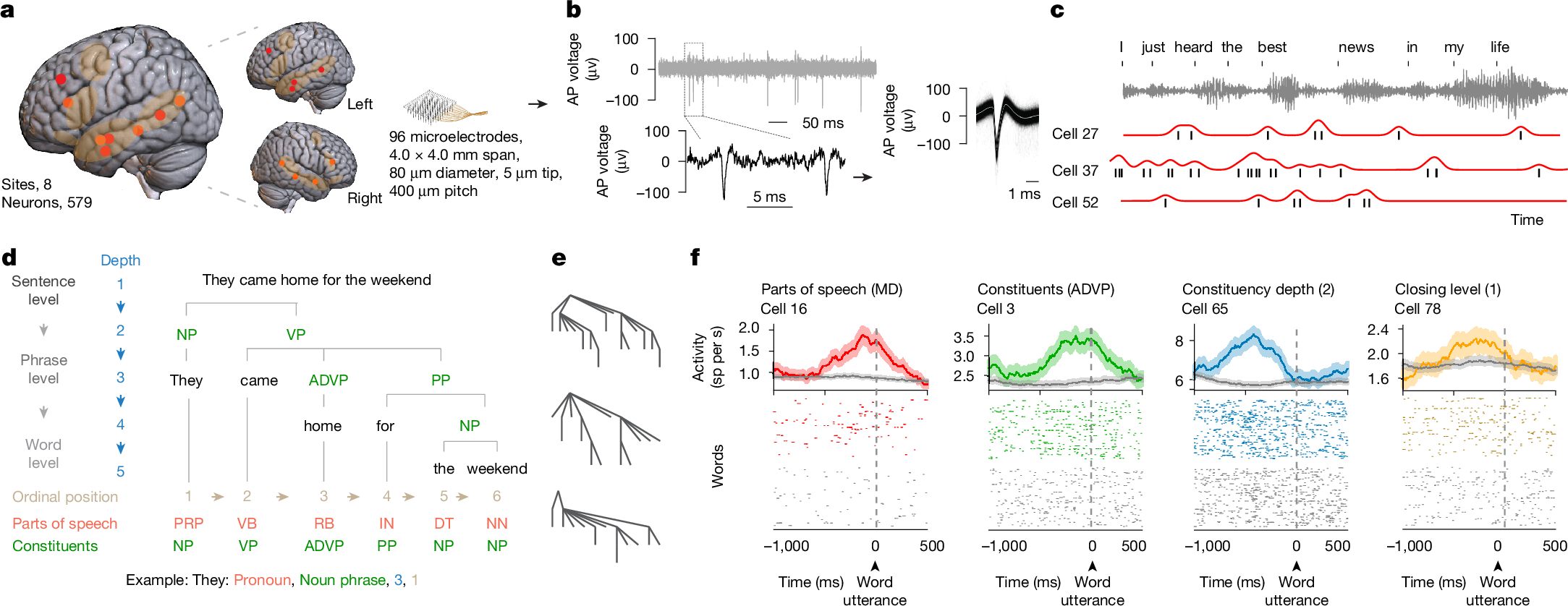
a, Sagittal views of microelectrode locations. Eight participants (579 neurons) were recorded from, with four sites located in the left hemisphere (n = 254 neurons) and four in the right hemisphere (n = 325 neurons). An overlay of the recorded sites (left), the recording sites by hemisphere64 (middle) and the approximate microelectrode dimensions (right) are shown. The highlighted areas represent regions that were previously identified to display language-selective responses on validated language localizers28,41,45 and reliably engage in speech production41,42,43,65,66. b, AP voltage tracings and waveform morphologies of well-isolated single units (one example out of n = 579 neurons) at varying timescales (left); each line represents a single AP (right). c, AP activities and raw audio waveforms time-aligned to each word. Spike timings for each cell are shown in black, and firing rate profiles are shown in red. n = 3 out of 579 neurons. d, For illustration, a constituency structure of a sentence, with each word labelled based on its respective part of speech (personal pronoun (PRP), verb (VB), adverb (RB), preposition (IN), determiner (DT), noun (NN)), constituents (noun phrase (NP), verb phrase (VP), adverb phrase (ADVP), prepositional phrase (PP)), constituency depth and ordinal position. e, Constituency structures of three representative sentences. f, Peri-word histograms (top) and raster plots (bottom) of four representative neurons, aligned to the onset of word utterance. The mean ± s.e.m. neuronal activity in spikes (sp) per second (s) is colour coded based on the linguistic feature that the neuron preferentially responded to. The coloured lines and dots reflect the features to which the neurons were preferentially tuned, whereas the grey lines and dots reflect the neuronal activity for all other features (Extended Data Fig. 1b). MD, modal.
During recordings, the participants produced various phrases and sentences during natural speech42,43,46,47,48 (see the ‘Language production and audio recordings’ section of the Methods). The sentences were also constructed de novo during natural language production (rather than simply read or repeated) and differed broadly in context and structure (Fig. 1c). For example, the participant may construct a declarative sentence such as “They came home for the weekend” or they may produce a sentence with a subject–verb inversion, such as “When is the payment due?” (Extended Data Table 1a; see the ‘Language production and audio recordings’ section of the Methods). Together, the participants produced 10,460 words across 1,895 sentences, for an average of 747 ± 168 (mean ± s.e.m.) words and 135 ± 28 sentences per neuron per session. All words produced by the participants were transcribed using a semiautomated platform and were aligned to each neuron’s AP activity (see the ‘Language production and audio recordings’ section of the Methods). The participants were English speakers and displayed normal language function on preoperative testing (see the ‘Participants’ section of the Methods).
Linguistic representations by neurons
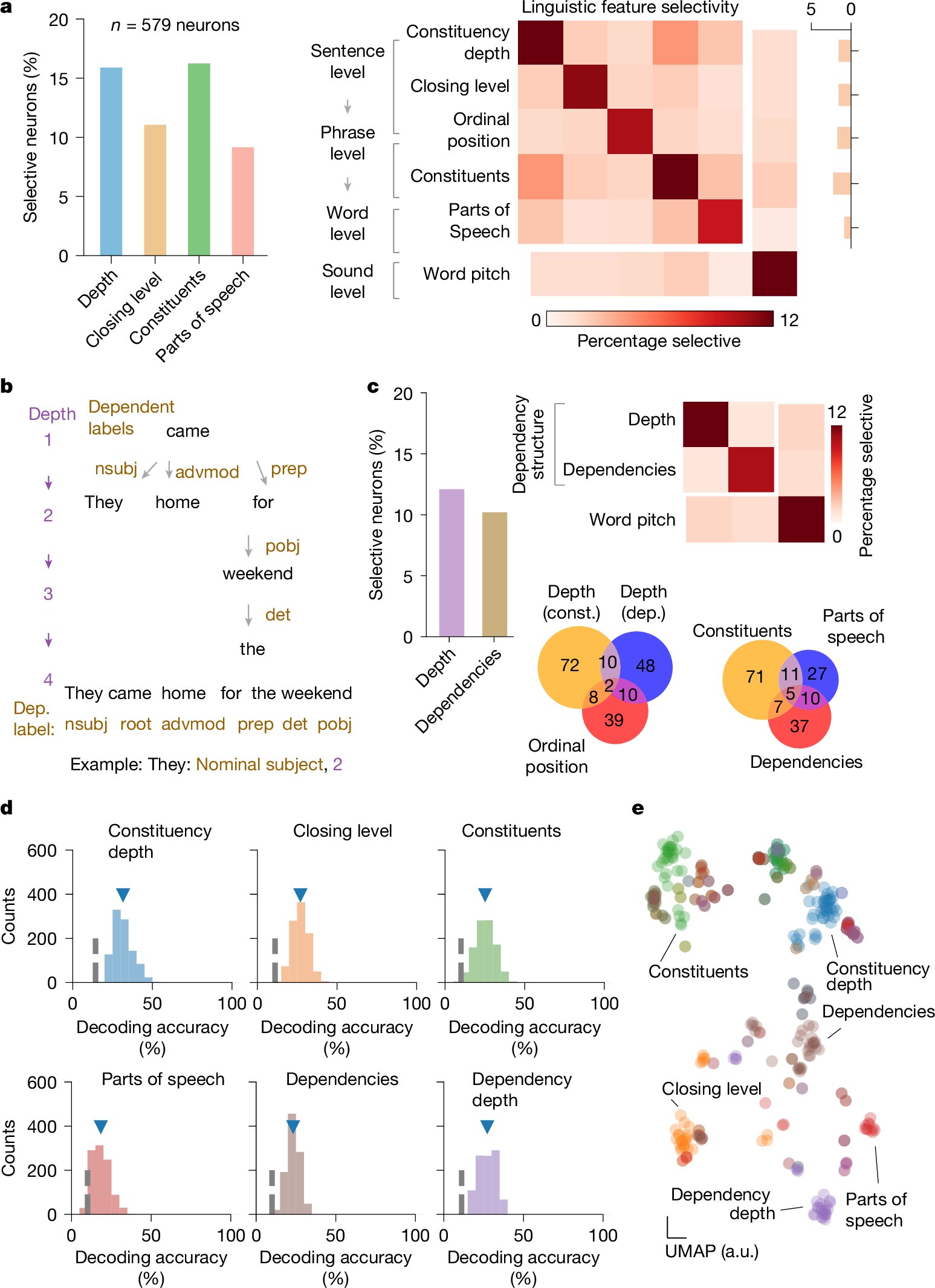
Neurons within the population responded selectively to the linguistic properties of the words. Natural language processing models such as context-sensitive constituency parsers allow for some of the core linguistic properties of words to be reliably labelled and tracked within natural speech1,2,3,49. Thus, for example, whereas the word’s part of speech reflects its grammatical properties (such as an adjective), the sentential constituents reflect how the word or group of words functions as a grammatical unit (for example, within a noun phrase). Furthermore, whereas the word’s constituency depth describes its hierarchical syntactic relationship to other words in a sentence, its ordinal position describes its rank order (Fig. 1d,e, Extended Data Fig. 1a and Extended Data Table 1b). By tracking the neurons’ AP activities in relation to each planned word (pre-articulation period, −400 ms to −100 ms from word utterance; see the ‘Single-neuronal analysis’ section of the Methods) and by using a constituency parsing approach (see the ‘Sentence parsing and linguistic feature labelling’ section of the Methods), we find that 9.2% (n = 53) of the neurons responded selectively to the words’ parts of speech (one-sided Mann–Whitney U-test, α = 0.05, P values were adjusted with false discovery rate (FDR) correction for multiple feature comparisons; Figs. 1f and 2a–c)—for example, transiently increasing their firing rates when the upcoming word was a modal verb (Fig. 1f and Extended Data Fig. 1b). By contrast, other neurons responded selectively to the sentence’s constituents (16.2%, n = 94), whereas 15.9% (n = 92) responded selectively to the word’s constituency depth (distance from the root of the constituency tree) and 11.1% (n = 64) to closing level (phrase mergers). Together, these proportions of neurons were significantly higher than expected from chance (χ2 test, P < 0.05) and remained consistent when randomly subsampling words (bootstrapping test, n = 100, P > 0.05 for all features; Extended Data Fig. 1c). They were also consistent when tested across statistical techniques such as multiple regression analyses and sequential feature selection that accounted for collinearities between features (χ2 test, P > 0.05 with Bonferroni correction across comparisons; Extended Data Table 1c), together suggesting that these neurons reflected the linguistic properties of the words.
 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.