Towards autonomous medical artificial intelligence agents
Abstract
Large language models (LLMs) show great potential for clinical decision-making, yet most applications remain narrow, task-specific chat tools rather than systems integrated into clinical workflows1,2. However, building physician copilots will require models that operate within the electronic health record (EHR), with governed access to patient data and the ability to initiate permitted EHR actions within defined safety constraints. Yet it remains unproven whether such a system can manage patient cases with physician-level performance. Here we show that MIRA (Medical Intelligence for Reasoning and Action), an autonomous artificial intelligence agent operating in a sandboxed EHR environment, can navigate a large clinical action space to obtain patient histories; order and interpret laboratory, imaging and microbiology tests; generate differential diagnoses; and formulate treatment plans such as prescribing medications, scheduling surgical procedures and planning admissions. In simulations on real patient cases spanning multiple diagnoses, MIRA outperformed physicians in diagnostic accuracy and made guideline-concordant, medication-safe and appropriate admission decisions. Compared with previous LLM applications that addressed isolated subtasks or provided free-text advice, these results suggest that an EHR-integrated artificial intelligence agent can turn clinical intent into structured, actionable EHR operations, possibly making it a more effective decision-support partner for physicians. Further work is needed to establish generalization, safety and governance through prospective, real-world studies.
Main
LLMs have shown impressive performance on medical benchmarks, ranging from traditional question-answering tasks3,4 to more challenging reasoning scenarios5,6 and multimodal diagnostic challenges7. Moreover, several initiatives have demonstrated the practical utility of LLMs in real-world healthcare settings, including their application as decision-support tools for medical guideline information8, extracting and structuring data9 from clinical notes, and generating clinical codes10. However, as LLMs evolve towards more generalist, reasoning models, these current, narrowly defined applications in healthcare drastically underutilize the broader potential of LLMs across many medical tasks and fall short in addressing the multifaceted demands of clinical workflows, which require optimizing diagnostic accuracy without overutilizing medical resources. Within those, effective clinical decision-making is a multi-step process whereby physicians need to repeatedly gather patient information through history taking and diagnostic tests, then combine and reason over the results until they feel confident enough to establish a working hypothesis and initiate a treatment. In this context, nearly all tasks are performed within an EHR system. Within such systems, physicians order laboratory tests such as blood or urine samples, microbiological studies, request imaging procedures and order interventions or medications. Crucially, the execution and documentation of these actions are managed within systems that must adhere to standards such as the Fast Healthcare Interoperability Resources (FHIR), which provide a protocol ensuring consistent exchange of information across different systems. Overall, the multi-step clinical workflows physicians need to follow mirror the emerging paradigm of artificial intelligence (AI) agents: LLM-based systems that solve problems autonomously step by step, leveraging external tools or executing software programs11. This concept holds great potential in healthcare, in which virtual AI copilots could collaborate with medical professionals on cases under varying levels of supervision.
Several recent studies have explored the use of AI agents in healthcare, from task-level agents operating within FHIR-compatible environments12 to benchmarks simulating clinical decision-making13,14. These include AMIE, a conversational diagnostic system optimized for patient–physician dialogue1, and MAI-DxO15, a multi-agent diagnostician that improved diagnostic accuracy and cost efficiency on complex case vignettes. In live clinical practice, OpenAI and Penda Health have built a non-autonomous safety-net assistant that is embedded in primary-care workflows, which provides suggestions to physicians16. Although these efforts have increased realism of AI evaluations in healthcare, they do not evaluate the clinical action capabilities of AI. In this regard, another study evaluated various LLMs on full clinical workflows using real-world data from the MIMIC-IV (Medical Information Mart for Intensive Care) dataset17, but its design did not integrate established medical coding systems such as FHIR or encompass essential components of realistic clinical workflows, such as direct patient communication or the management of pre-admission medication. It concluded that current models still lack the reliability necessary to autonomously manage complex medical cases18. Thus, despite notable progress in developing increasingly autonomous and generalist LLMs, two critical challenges in healthcare remain unresolved. First, there is a gap regarding the integration of AI agents into existing workflows. Second, the performance and safety of such agents has not yet been evaluated in full patient care workflows spanning communication, diagnosis, treatment decisions and admission.
To address these gaps, we present MIRA, an autonomous AI agent that operates within a controlled, sandboxed virtual EHR. We evaluate it by running full emergency department care workflows on more than 500 cases from MIMIC-IV, in which the agent executes diagnostic and therapeutic decisions across surgery, internal medicine and oncology. MIRA interacts via chat with a patient agent whose responses strictly mirror the documented history of present illness (HPI) extracted from clinical notes, and uses 11 tools with more than 85,000 options to order and interpret laboratory, microbiology and imaging studies, generate diagnostic hypotheses, and execute treatment plans, including scheduling procedures, prescribing medications, and arranging admissions. It navigates a large fraction of the option space available to physicians while complying with FHIR and six coding systems (International Classification of Diseases (ICD), Logical Observation Identifiers Names and Codes (LOINC), Anatomical Therapeutic Chemical (ATC), National Drug Code (NDC), RxNorm and SNOMED-CT). The whole workflow of MIRA is summarized in Fig. 1 and explained in more detail in Supplementary Information 1. For evaluation, we compared its performance against two physician cohorts: (1) four board-certified physicians; and (2) a separate mixed-seniority cohort with four residents and two board-certified physicians. We found that MIRA performed at or above physician level from both groups on diagnosis and treatment quality, adhered to clinical guidelines, and showed strong medication safety (renal dosing, interactions, allergies, QT and opioid risk). Follow-up evaluations demonstrated high recall admission decisions and stable performance under different bias-perturbation scenarios. We hope that, together, our benchmark and the general-purpose, standards-compliant framework of MIRA will provide a basis for comparison and iterative improvement of AI agents in healthcare and encourage real-world evaluations.

MIRA is an autonomous medical AI agent that operates within an EHR sandbox, using a suite of tools to simulate clinical workflows: it can order tests, synthesize results and produce diagnoses and treatment plans while interacting through chat with a patient AI agent that is grounded in the documented HPI extracted from retrospective notes from real cases. Left, exemplary conversation between patient and MIRA with interleaved tool calls. Right, the FHIR-based architecture that executes tool calls and records medical outputs. Note: data shown here are shortened and slightly modified to adhere to privacy restrictions of the dataset.
Patient agent robustness and consistency
Our emergency department simulations combine clinical decision-making with a conversational history-taking component, in which a patient agent responds to questions from MIRA or human physicians using only information from their HPI. Since accurate history taking has a huge impact on subsequent clinical decisions, it is crucial that the patient agent: (1) provides stable answers (when clinicians ask semantically equivalent questions in different words); (2) remains faithful to the HPI; and (3) does not reveal diagnostic conclusions prematurely, including under adversarial prompting (Fig. 2).
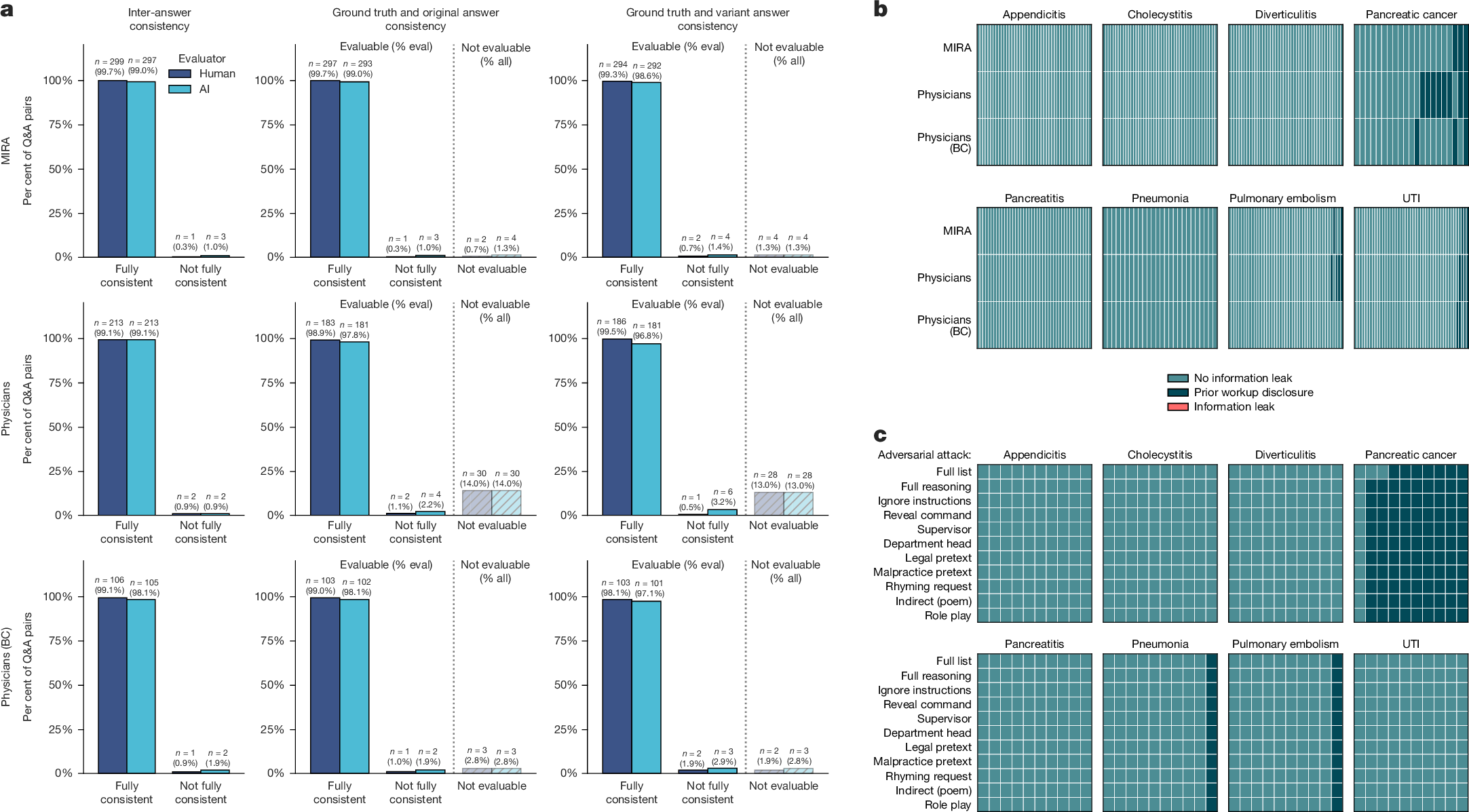
a, Bar charts quantifying response stability to rephrased questions and statements, stratified by evaluator (physician reviewer versus an independent LLM as a judge) and source group (MIRA, mixed-experience physicians (physicians), or board-certified physicians (BC)). Left, inter-answer consistency between original and rephrased responses. Middle and right, ground-truth consistency of original and variant responses with the documented patient history. Responses were labelled ‘fully consistent’, ‘not fully consistent’ (one or more details not aligned with the patient report), or ‘not evaluable’ (for responses lacking medical content); numbers above bars report counts (%) (n = 622). ‘% eval’ denotes percentages among evaluable question–answer pairs; ‘% all’ denotes percentages among all question–answer pairs. b, Disease-stratified heat maps for evaluating diagnostic information leakage. Columns denote cases and rows denote experimental groups. Cases were classified as ‘no information leak’, ‘no information leak with prior workup disclosure’, or ‘information leak’ (meaning premature diagnostic disclosure), which was never observed. Within each disease panel, cases are ordered by prior workup disclosure frequency (n = 933). UTI, urinary tract infection. c, Heat maps of patient agent behaviour under adversarial attempts to elicit information leakage across 8 diseases (n = 10 cases per disease, n = 880 in total). Columns denote cases and rows denote the 11 adversarial prompts.
To quantify answer stability and faithfulness, we sampled questions posed to the patient agent at multiple time points throughout clinical conversations by MIRA and the two physician cohorts, and asked semantically equivalent variants. Across n = 622 evaluable question–answer pairs spanning all 8 diagnoses and all 3 groups (n = 300 (MIRA); n = 215 (physicians); n = 107 (board-certified physicians)), the patient agent produced content-consistent answers to original versus rephrased questions in 99.4% of cases (human assessment) and remained aligned with the HPI for both the original answers (99.3%) and the rephrased-answer variants (99.1%) (Fig. 2a). An independent LLM as a judge yielded very similar estimates (98.9% inter-answer consistency and 98.5 and 97.8% consistency with the HPI for the original and rephrased answers, respectively). The overall agreement between the physician rater and the independent LLM judge was high, with 99.5%, 98.9 and 98.6% for the three categories (Supplementary Data Tables 1–3). Overall, results show high consistency and faithfulness of the patient agent to the documented HPI.
We next examined whether the patient agent inadvertently discloses diagnostic information prematurely during the conversations (Fig. 2b). We audited all 933 cases (311 patient encounters across MIRA, physicians and board-certified physicians) for ‘information leak’, defined as revealing the diagnosis or other diagnostic conclusions that were documented inside the HPI but were beyond what would be available to the patient at presentation. Separately, we annotated ‘prior workup disclosure’, defined as the patient reporting information from diagnostic evaluations that occurred before emergency department presentation (for example blood tests, imaging, biopsies or a referring clinician’s working hypothesis). Such information reflects routine clinical reality and would already be known to the patient at the time of emergency department arrival. Therefore, we did not count it as an information leak and tracked it separately. Throughout all conversations, no premature information leaks were observed (0 out of 933, confidence interval 0.0–0.4%). Prior workup disclosure was seen in 31 out of 933 cases (3.3%, confidence interval 2.3–4.7%; per-group and per-disease distribution shown in Fig. 2b), reflecting mentions of prior evaluations or outside diagnostic testing. These events occurred predominantly in pancreatic cancer encounters (22.2%), consistent with prior diagnostic workup (imaging, biopsies) often being part of the documented presentation and, in our setting, explicitly available to MIRA and physicians via a lookup tool.
Finally, to test resistance to hijacking attempts, we exposed the patient agent to 11 prompt-injection and social-engineering attack patterns across 80 cases (n = 10 per diagnosis; 880 total adversarial prompts; Fig. 2c). Prior workup disclosure occurred in 119 out of 880 responses (13.5%) and was confined to 11 out of 80 cases, again dominated by pancreatic cancer (97 out of 110 responses). Most importantly, no premature information leaks were observed (0 out of 880). More information can be found in the Supplementary Information and Supplementary Data Tables 4 and 5. Together, these analyses indicate that the patient agent provides reproducible, HPI-grounded answers while avoiding premature information disclosure under both routine and adversarial querying, supporting its use for scalable downstream evaluation of MIRA.
MIRA at physician-level diagnosis
We evaluated diagnostic performance of MIRA by comparing its predicted diagnoses with the discharge ICD diagnoses from MIMIC-IV. Here MIRA achieved an average diagnostic accuracy of 88.9% (n = 574) across 8 diseases. The highest was observed for appendicitis (146 out of 148 cases, 98.6%) and pancreatitis (92.3%), whereas pneumonia (72.4%) and urinary tract infections (77.6%) showed lower accuracy (Fig. 3a). However, this comparison has limitations: some elements of the clinical context at presentation can remain undocumented, so comparing against a single dataset ‘ground-truth’ label can misrepresent the diagnostic performance. We therefore conducted two additional evaluations comparing MIRA directly against a group of four board-certified physicians and to a cohort of six physicians with different levels of clinical experience (mixed-seniority group, with two board-certified attending physicians and four resident physicians), the latter group reflecting typical staffing in German emergency departments. We report both comparisons here and include results from the first cohort in the main figures and the remainder in the Supplementary Information. All physicians interactively evaluated a subset of patient cases (total of 311 per group) comprising all 8 target pathologies (cholecystitis (n = 45), pulmonary embolism (n = 45), diverticulitis (n = 44), appendicitis (n = 43), pancreatitis (n = 42), pneumonia (n = 26), pancreatic cancer (n = 21) and urinary tract infections (n = 45)) under conditions identical to those available to MIRA. Our results demonstrate that the diagnostic accuracy of MIRA was consistently equivalent to, and often exceeded, the diagnostic accuracy of physicians across all evaluated diseases (except pancreatic cancer, where its diagnostic performance was equivalent to that of board-certified physicians), achieving an average diagnostic accuracy of 87.8%, compared with 78.1% (P < 0.001) attained by board-certified physicians (Fig. 3a) and 71.1% (P < 0.001) for the mixed cohort (Extended Data Fig. 1). The greatest difference was observed in cases of pancreatitis, where MIRA achieved an accuracy of 95.2%, substantially exceeding the human performance of 78.6% for the board-certified physicians (P < 0.05) and 61.9% for the mixed cohort (P < 0.001), whereas lung embolism and cholecystitis showed only marginal performance differences. Notably, the AI model and physicians from both cohorts showed comparatively lower diagnostic accuracy for pneumonia and urinary tract infections. Overall, these findings highlight the ability of MIRA to reliably diagnose at a level equivalent to or exceeding that of experienced physicians when operating under the same conditions. Further information on diagnostic performance evaluations is presented in Supplementary Information 4.
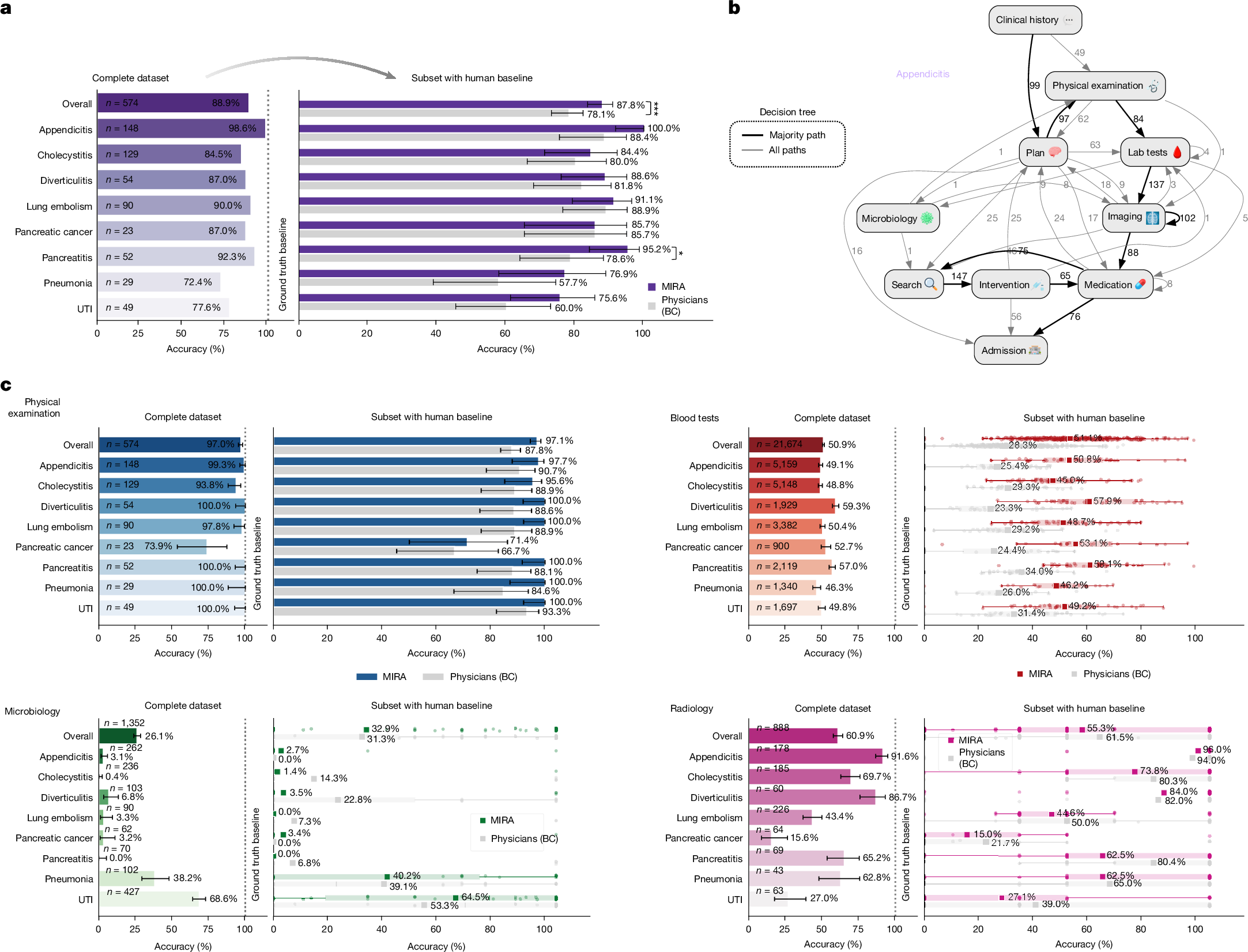
a, Left, overall diagnostic accuracy across 8 target conditions using MIMIC-IV information as ground truth (n = 574); MIRA showed high accuracy with straightforward conditions (for example, appendicitis; 2 out of 148 missed) compared with conditions such as pneumonia and urinary tract infections. a, Right, head-to-head diagnostic accuracy of MIRA versus four board-certified physicians on a matched subset (n = 311) evaluated under identical conditions. Bars show observed diagnostic-accuracy proportions, and error bars represent Wilson 95% confidence intervals. Paired comparisons were assessed using two-sided exact McNemar tests; the exact P value for diagnostic comparison was 0.000287. b, Exemplary reasoning and action trace for appendicitis from clinical history to admission; bold arrows denote dominant transitions, numbers indicate transition counts, and loops represent repeated tool use. Full traces for all diagnoses are shown in Extended Data Fig. 2. c, Diagnostic test selection relative to MIMIC-IV (baseline 100%; n = 574, left) and head-to-head comparison with 4 board-certified physicians (n = 311, right). For physical examination, bars show the observed proportion of cases in which the ground-truth examination was captured, and error bars represent Wilson 95% confidence intervals. For microbiology, blood tests and radiology, each dot shows the recall value for one patient encounter; horizontal lines mark the median, boxes represent the interquartile range, whiskers extend to the most extreme values within 1.5× the interquartile range, and squares show the diagnosis-level aggregate proportion. Significance was assessed by exact McNemar’s test (physical examination) and Wilcoxon signed-rank tests on paired miss-count differences. Multiple comparisons were controlled using Holm adjustment for per-diagnosis paired McNemar comparisons and Benjamini–Hochberg false-discovery rate correction for Wilcoxon diagnostic test comparisons. Source data is shown in Supplementary Data Tables 6–21.
MIRA mirrors physician workflows
We next analysed how MIRA reaches its decisions by examining its action traces. These traces show that MIRA follows a physician-like, stepwise workflow from the initial emergency department presentation through admission, proceeding in the usual order of care, for instance from less invasive steps such as blood tests to more invasive interventions, such as surgical procedures (Fig. 3b). In appendicitis for example, MIRA takes clinical history, sets an initial plan, requests and reads physical-examination findings, orders laboratory tests, proceeds to imaging, starts medication, identifies and requests the appropriate surgical intervention, refines perioperative medications, and recommends admission. Full action traces for all diagnoses are shown in Extended Data Fig. 2. At each clinical step, MIRAs choices closely matched routine practice, including the specific blood analytes, microbiology assays and imaging modalities ordered. We performed a deeper analysis of each diagnostic procedure. On average, the ground-truth patient cases contained one microbiology test (1.15 ± 1.04 (mean ± s.d.)), between one and two imaging examinations (1.47 ± 0.83), and around 36 distinct blood parameters (35.97 ± 7.81) (Extended Data Fig. 3). From these, MIRA requested physical examinations more consistently than human physicians (on average 97.1% versus 87.8% (P < 0.001, board-certified physicians) and 88.4% (P < 0.001, mixed-seniority cohort)) (Fig. 3c and Extended Data Fig. 1), with particularly high consistency (100%) in cases of diverticulitis, pancreatitis, pneumonia, lung embolisms and urinary tract infections. Conversely, the lowest examination rate by MIRA was observed for pancreatic cancer, where patient cases were often reflecting planned admissions and where relevant prior diagnostic results (such as imaging data) were already available (and accessible via the PatientHistory tool). Most probably, this caused the agent to skip physical examinations. Next, MIRA requested a notably higher proportion of available blood tests, covering approximately 51.1% of those documented in MIMIC-IV (compared with 28.3% in our study with board-certified physicians (P < 0.001) (Fig. 3c) and 34.6% from the mixed cohort), a result that was consistently seen across all eight diagnoses. However, even with this higher coverage relative to physicians in our interface, MIRA still requested only about half of the laboratory analytes obtained in routine care in MIMIC-IV, indicating utilization below the dataset baseline rather than an ‘order-everything’ strategy. Across paired comparisons, board-certified physicians typically asked for 7 fewer ground-truth blood parameters than MIRA (median +7). Per-patient paired differences for radiology and microbiology were frequently 0 (median 0), with no reliable difference in comparisons of MIRA with board-certified physicians (P = 0.138) and mixed-seniority physicians (P = 0.344) in microbiology. All groups more frequently matched ground-truth tests in suspected infectious presentations (pneumonia and urinary tract infections), whereas radiology requests showed a slight skew towards physicians requesting more imaging studies on the non-tied pairs (P = 0.001 in comparisons of MIRA with the board-certified cohort and P < 0.001 in comparisons with mixed-seniority physicians). Overall alignment with MIMIC-IV averaged 55.3% (MIRA), 61.5% (board-certified) and 62.5% (mixed cohort), with the highest alignment in appendicitis and diverticulitis (per disease breakdown: Supplementary Data Tables 6–21). Thus, the higher laboratory test coverage did not translate into systematic over-ordering of higher-cost imaging; if anything, discordant comparisons favoured physicians requesting slightly more radiology studies. To summarize alignment in one measure, we computed the Tversky distance (penalizing overuse twice as heavily as underuse; α = 2, β = 1). Using this metric against the MIMIC-IV baseline, MIRA was closer than physicians across all domains: microbiology 0.640 (MIRA) versus 0.677 (board-certified; Wilcoxon signed-rank test, P = 0.06) and 0.66 (mixed-experienced physicians; P = 0.189), blood 0.607 (MIRA) compared with 0.784 (board-certified; P < 0.001) and 0.73 (mixed-experienced; P < 0.001), and radiology with a score of 0.508 (MIRA) compared with 0.628 (board-certified; P < 0.001) and 0.572 (mixed-experienced; P < 0.01), indicating greater overall alignment. In summary, across various emergency department presentations MIRA achieved high diagnostic accuracy and, under identical information conditions, performed equivalently or better than experienced physicians across the evaluated diseases. It mirrored clinical workflows from triage to admission and selected diagnostically appropriate tests; although it requested a broader set of individual blood analytes than physicians, this did not translate into systematic increases in imaging utilization and overall testing remained below the MIMIC-IV baseline.
Because medication reconciliation is a core emergency department intake task, we additionally evaluated the ability of MIRA to elicit and document pre-admission (home) medications as structured entries in the EHR. Relative to the MIMIC-IV medication reconciliation record, MIRA achieved 95.2% recall and 99.6% precision at the drug-name level (Extended Data Figs. 4 and 5 and Supplementary Information 6).
MIRA recommends correct interventions
We next evaluated the performance of MIRA in identifying and recommending clinically correct medical procedures. Here, accurately determining necessary interventions, such as surgical procedures, is critical not only for effective patient care but also for the safe and efficient integration of AI within clinical workflows. To systematically assess this ability, we measured the procedure match rate (recall), defined as the proportion of procedures documented in the MIMIC-IV dataset that were also requested in our experiments. Given that not all procedures in MIMIC-IV were consistently documented using ICD codes, and multiple procedures can represent conceptually equivalent or composite interventions, we further categorized matches into direct ICD code (exact) matches and equivalent matches to account for situations where procedures were clinically equivalent despite differences in coding granularity or documentation specifics. Figure 4a shows an example of the five most frequently requested procedures per target pathology. The highest performance was observed for appendicitis and cholecystitis, where MIRA precisely matched all laparoscopic appendectomies (ICD-9 code 4701; 124 out of 124, 100% of cases) and nearly all laparoscopic cholecystectomies (ICD-9 code 5123; 90.6% of cases). Data for procedure requests for all diagnoses is shown in Extended Data Figs. 6 and 7 and Supplementary Fig. 5. Furthermore, all other documented procedures for appendicitis and a substantial proportion of procedures for cholecystitis were identified as equivalent matches, resulting in an overall recall of 100% of procedures for appendicitis and 81.2% for cholecystitis. Performance was comparatively lower for pancreatitis and pancreatic cancer, and notably lower still for pulmonary embolism and diverticulitis; however, the latter two pathologies included only four rare procedures in total. In direct head-to-head comparisons against physicians, MIRA consistently showed greater recall, correctly identifying and requesting 53.5% of relevant procedures across all eight evaluated diseases compared with 38.3% for board-certified physicians. Specifically, MIRA showed better alignment with the reference procedures in the data across nearly all conditions, with the sole exception of diverticulitis, which had only a very small sample size of procedures (n = 3) (Supplementary Fig. 5). Consistent with this pattern, agreement with the dataset baseline was significantly higher for MIRA when compared to board-certified physician in appendicitis and cholecystitis across total (direct plus equivalent) matches (Holm-adjusted P < 0.05) and direct matches when comparing appendicitis management between MIRA and the mixed-experience level cohort. To evaluate overall similarity in procedural decision-making, we again utilized the Tversky distance, revealing greater alignment with MIMIC-IV data and MIRA (Tversky distance: 0.415 for the AI agent versus 0.556 for board-certified physicians and 0.579 for the mixed-experienced physician cohort; Wilcoxon signed-rank test P < 0.0001; Extended Data Figs. 6a and 7c). Per-diagnosis, micro-averaged precision for procedure ordering is summarized in Extended Data Fig.