Vectorized instructive signals in cortical dendrites
TL;DR
This study demonstrates that cortical dendrites implement vectorized instructive signals for credit assignment in the brain, using a neurofeedback BCI task in mice. Dendritic activity encodes task-related information like reward and error, and disrupting these signals impairs learning.
Key Takeaways
- •Vectorized instructive signals in cortical dendrites solve the credit assignment problem by tailoring teaching signals to individual neurons.
- •Dendritic activity contains task-related information (e.g., reward, error) not fully present in somatic activity, reflecting neuron-specific contributions.
- •Optogenetic perturbation of dendritic signals disrupts learning, confirming their functional role in neural adaptation.
- •The study uses a neurofeedback BCI task to specify reward functions, enabling direct testing of subcellular learning mechanisms.
Tags
Abstract
Vectorization of teaching signals is a key element of almost all modern machine learning algorithms, including backpropagation, target propagation and reinforcement learning. Vectorization allows a scalable and computationally efficient solution to the credit assignment problem by tailoring instructive signals to individual neurons. Recent theoretical models have suggested that neural circuits could implement single-phase vectorized learning at the cellular level by processing feedforward and feedback information streams in separate dendritic compartments1,2,3,4,5. This presents a compelling, but untested, hypothesis for how cortical circuits could solve credit assignment in the brain. Here we used a neurofeedback brain–computer interface task with an experimenter-defined reward function to test for vectorized instructive signals in dendrites. We trained mice to modulate the activity of two spatially intermingled populations (four or five neurons each) of layer 5 pyramidal neurons in the retrosplenial cortex to rotate a visual grating towards a target orientation while we recorded GCaMP activity from somas and corresponding distal apical dendrites. We observed that the relative magnitudes of somatic and dendritic signals could be predicted using the activity of the surrounding network and contained information about task-related variables that could serve as instructive signals, including reward and error. The signs of these putative teaching signals depended on the causal role of individual neurons in the task and predicted changes in overall activity over the course of learning. Furthermore, targeted optogenetic perturbation of these signals disrupted learning. These results demonstrate a vectorized instructive signal in the brain, implemented via semi-independent computation in cortical dendrites, unveiling a potential mechanism for solving credit assignment in the brain.
Similar content being viewed by others
Inferring neural activity before plasticity as a foundation for learning beyond backpropagation
Foundation model of neural activity predicts response to new stimulus types
Specialized structure of neural population codes in parietal cortex outputs
Main
Learning is the product of changes in the strength of synaptic connections between neurons6,7,8,9,10,11,12,13. Synaptic modifications can have difficult-to-predict effects on network output, particularly in complex hierarchical networks such as the brain. The challenge of determining how individual synapses should be altered to improve task performance is known as the credit assignment problem14,15,16,17,18. Whereas this problem is effectively solved in artificial neural networks (ANNs) by the backpropagation-of-error algorithm19, how credit assignment is solved in the brain remains unknown14,15.
Recent theoretical work has proposed several models by which biological circuits could solve credit assignment, including target learning and backpropagation-like algorithms1,2,3,4,5,20,21. Central to both artificial and biologically inspired solutions to credit assignment is the vectorization of instructive signals, as opposed to the broadcasting of a single scalar teaching signal14. Effective learning requires, in addition to vectorization, instructive signals to be separable from feedforward inputs to prevent interference15. In ANNs, this is achieved via temporal separation, which has long been thought to be biologically implausible. One hypothesis is that in cortex, credit-related information is spatially, rather than temporally, segregated in the apical dendrites of pyramidal neurons15. This aligns with anatomical and circuit evidence that feedforward inputs are received perisomatically and feedback inputs are received in the distal dendrites22,23,24,25,26,27,28,29,30,31. However, direct evidence regarding the subcellular mechanisms of credit assignment is lacking.
Vectorized teaching signals at the dendritic level should meet four experimentally testable conditions. First, dendritic activity should contain information that is not present in somatic activity alone (although somas could theoretically transmit gradients using qualitatively different spiking patterns2,4,32, the cable properties of dendrites predict some level of independence between somatic and dendritic activity). Second, dendritic activity should encode information about task performance that could serve as instructive signals, such as reward and error representations. Third, dendritic activity should reflect the contribution of that neuron to task performance (that is, the reward function). Fourth, disrupting vectorized instructive dendritic signals should impair learning.
Specifying a reward function using a BCI task
Evaluating credit assignment in biological neural networks has thus far proved impossible14,15. Teaching signals can only be defined relative to a reward function that maps neural activity to task performance. It is unclear whether such functions are explicitly represented in the brain. Even if they are, experimenters are blind to their specific formulation in terms of neural activity15. Neurofeedback brain–computer interface (BCI) tasks present a potential solution to this problem by directly coupling neural activity to task performance, thereby allowing the experimenter to specify the reward function to be optimized14,20,21. Previous studies have shown that mice are able to learn BCI tasks using a variety of feedback stimuli and brain areas and that learning induces changes in the activity of the neurons controlling the BCI, including in the hippocampus and various sensory and motor cortices33,34,35,36,37,38,39. Here we leveraged a visually guided neurofeedback BCI task in cortical pyramidal neurons to test subcellular mechanisms for error and reward-related signalling (Fig. 1a–c and Supplementary Figs. 1 and 2). We trained head-fixed mice under a 2-photon microscope to control the activity of two spatially intermingled sets of GCaMP7f-labelled layer 5 pyramidal neurons, in the retrosplenial cortex (RSC), designated P+ and P− (selection criteria in Extended Data Figs. 1 and 4b and Methods). The difference in mean somatic GCaMP activity of P+ versus P− neurons was coupled to rotation of a visual grating relative to a rewarded target angle33,34,35,36,38,39 (Fig. 1d–f and Supplementary Data Fig. 1). We selected RSC owing to the optical accessibility of layer 5 and previous demonstration of independent dendritic events in this area40. We recorded GCaMP activity at 15 Hz in the proximal trunk dendrite as a proxy for somatic activity; this allowed imaging of many neurons while reducing signal contamination owing to the more precise spatial footprint and faster signal kinetics of the apical trunk41,42,43. We measured task performance with two metrics: accuracy, which represented the fraction of rewarded trials; and speed, which represented the number of rewards obtained per minute. Mice (n = 6) learned the task by both metrics (Fig. 1g and Extended Data Fig. 2 and 3).
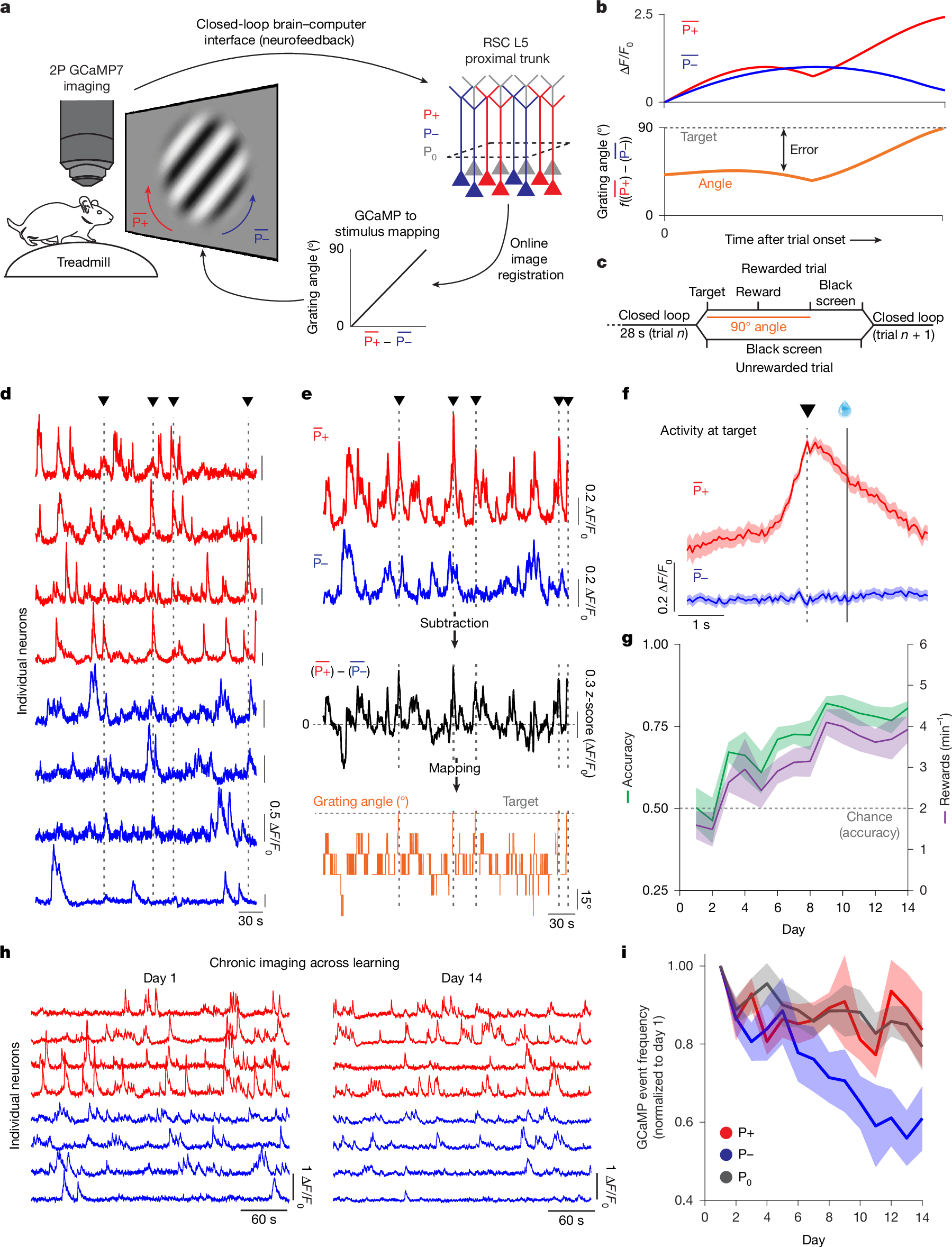
a, Schematic of the BCI setup. Mice were head-fixed and imaged under a 2-photon (2P) microscope and free to run on a cylindrical treadmill. Two user-defined populations of GCaMP7f-labelled layer 5 (L5) pyramidal neurons in RSC were imaged at the proximal apical trunk: P+ (red) and P− (blue) were selected to control the rotation of a Gabor patch. P0 neurons were designated as all other neurons in the field of view. Single frames were online-registered (motion-corrected). Activity in P+ neurons rotated the patch clockwise, towards the target angle of 90°. Activity in P− neurons rotated the Gabor patch stimulus counter-clockwise, towards a 0° angle. b, Schematic of the mapping between P+ and P− activity, stimulus angle, target activity and error. Error was the distance between current and target activation. The angle represents a binned (7 bins, 15° apart, from 0° to 90°) linear mapping between the mean activity in P+ neurons minus the activity in P− neurons. c, Trial structure: mice had 28 s to reach target activity and receive a reward, delivered 1 s later. In successful trials, the 90° Gabor patch was shown for 2 s, followed by 1 s of black screen presentation. In unsuccessful trials, a 3 s black screen was presented before the onset of the next trial. d, ΔF/F0 traces as recorded live for P+ (red) and P− (blue) neurons. Vertical dashed lines and triangles represent timepoints where the mouse reached target activity. e, Mean activity for the red (P+) and blue (P−) traces shown in d. The black trace shows the arithmetic subtraction of P+ and P− neurons (z-scored). The orange trace shows the corresponding visual stimulus angle as presented to the mouse. f, Mean ΔF/F0 for P+ and P− activity aligned to the time in which the mouse reached target activity (dashed, vertical line and black triangle) for the session highlighted in d,e. Reward was delivered 1 s later (solid vertical line with water reward). Shaded areas represent s.e.m. g, Mean performance over days quantified as the fraction of successful trials over the total number of trials and as the number of rewards per minute (one-way repeated measures ANOVA, P = 5 × 10−4 (accuracy) and P = 0.002 (rewards per minute); n = 6 mice). The dashed horizontal red line represents chance level for accuracy performance (Methods). Shaded areas represent s.e.m. h, ΔF/F0 traces for the same P+ and P− neurons on training day 1 and training day 14. i, Calcium transient frequency for P+, P− and P0 neurons across the 14 days of training normalized to the activity on day 1. All neurons were tracked over the full 14 days of imaging. Two-way repeated measures ANOVA, P = 0.012, P = 0.004 and P = 9.3 × 10−4 for the effect of population identity, days and an interaction between population identity and days. After Tukey’s multiple comparison, P = 0.027 (P+ versus P− neurons), P = 0.95 (P+ versus P0 neurons) and P = 0.01 (P− versus P0 neurons). n = 6 mice. Shaded areas represent s.e.m.
We compared activity levels of P+ and P− populations, as well as the population of surrounding neurons that were not directly involved in the rotation of the stimulus (termed P0), across days of task performance. We imaged the same neurons longitudinally throughout all experiments. We found that learning was accompanied by the differential regulation in the activity of P+ and P− neurons over days (Fig. 1h,i), with P+ neurons maintaining their activity levels while P− neurons were downregulated. Whereas, on average, changes in activity in P0 neurons resembled changes in P+ neurons (Fig. 1i), selecting the subpopulation of P0 neuron with matching activity levels of P+ and P− neurons on day 1 revealed that changes in activity in P0 neurons fell in between those of P+ and P− neurons (Extended Data Fig. 4). As the most active neurons on day 1 were also those that were most strongly downregulated (Extended Data Fig. 4c), our results are consistent with a model of learnin