Multimodal learning with next-token prediction for large multimodal models
TL;DR
Emu3은 단순한 다음 토큰 예측만으로 텍스트, 이미지, 비디오를 통합 학습하는 다중모달 모델입니다. 확산 모델이나 조합적 접근 없이도 생성과 이해에서 기존 작업별 모델과 동등한 성능을 보이며, 비디오 생성과 로봇 조작까지 지원합니다.
Key Takeaways
- •Emu3은 다음 토큰 예측만으로 텍스트, 이미지, 비디오를 통합 학습하는 다중모달 모델로, 확산 모델이나 조합적 접근을 제거합니다.
- •이미지 생성, 비디오 생성, 비전-언어 이해에서 기존 작업별 모델과 동등한 성능을 달성하며, 확장 가능한 통합 토큰화와 디코더 전용 아키텍처를 활용합니다.
- •비디오 생성은 순수 인과적 방식으로 자동회귀적으로 수행되며, 텍스트-비디오 생성에서 확산 모델과 경쟁력 있는 결과를 보입니다.
- •비전-언어-액션 모델링을 통해 로봇 조작에 적용 가능하며, 직접 선호도 최적화(DPO)를 통한 인간 선호도 정렬을 지원합니다.
- •통합 학습은 안정적인 스케일링 법칙을 따르며, 모델 크기와 데이터 규모에 따라 예측 가능한 성능 향상을 보입니다.
Tags
Abstract
Developing a unified algorithm that can learn from and generate across modalities such as text, images and video has been a fundamental challenge in artificial intelligence. Although next-token prediction has driven major advances in large language models1, its extension to multimodal domains has remained limited, and diffusion models for image and video synthesis2,3 and compositional frameworks that integrate vision encoders with language models4 still dominate. Here we introduce Emu3, a family of multimodal models trained solely with next-token prediction. Emu3 equals the performance of well-established task-specific models across both perception and generation, matching flagship systems while removing the need for diffusion or compositional architectures. It further demonstrates coherent, high-fidelity video generation, interleaved vision–language generation and vision–language–action modelling for robotic manipulation. By reducing multimodal learning to unified token prediction, Emu3 establishes a robust foundation for large-scale multimodal modelling and offers a promising route towards unified multimodal intelligence.
Similar content being viewed by others
Leveraging multimodal large language model for multimodal sequential recommendation

On opportunities and challenges of large multimodal foundation models in education
MMAgentRec, a personalized multi-modal recommendation agent with large language model
Main
Since AlexNet5, deep learning has replaced heuristic hand-crafted features by unifying feature learning with deep neural networks. Later, Transformers6 and GPT-3 (ref. 1) further advanced sequence learning at scale, unifying structured tasks such as natural language processing. However, multimodal learning, spanning modalities such as images, video and text, has remained fragmented, relying on separate diffusion-based generation or compositional vision–language pipelines with many hand-crafted designs. This work demonstrates that simple next-token prediction alone can unify multimodal learning at scale, achieving competitive results with long-established task-specialized systems.
Next-token prediction has revolutionized the field of language models1, enabling breakthroughs such as ChatGPT7 and sparking discussions about the early signs of artificial general intelligence8. However, its potential in multimodal learning has remained uncertain, with little evidence that this simple objective can be scaled across modalities to deliver both strong perception and high-fidelity generation. In the realm of multimodal models, vision generation has been dominated by complex diffusion models2, whereas vision–language perception has been led by compositional approaches9 that combine CLIP10 encoders with large language models (LLMs). Despite early attempts to unify generation and perception, such as Emu11 and Chameleon12, these efforts either resort to connecting LLMs with diffusion models or fail to match the performance of task-specific methods tailored for generation and perception. This leaves open a fundamental scientific question: can a single next-token prediction framework serve as a general-purpose foundation for multimodal learning?
In this work, we present Emu3, a new set of multimodal models based solely on next-token prediction, eliminating the need for diffusion or compositional approaches entirely. We tokenize images, text and videos into a discrete representation space and jointly train a single transformer from scratch on a mix of multimodal sequences. Emu3 demonstrates that a single next-token objective can support competitive generation and understanding capabilities, while being naturally extendable to robotic manipulation and multimodal interleaved generation within one unified architecture. We also present the results of extensive ablation studies and analyses that demonstrate the scaling law of multimodal learning, the efficiency of unified tokenization and the effectiveness of decoder-only architectures.
Emu3 achieves results comparable with those of well-established task-specific models across both generation and perception tasks, equals the performance of diffusion models in text-to-image (T2I) generation, and rivals compositional vision–language models that integrate CLIP with LLMs in vision–language understanding tasks. Furthermore, Emu3 is capable of generating videos. Unlike Sora3, which synthesizes videos through a diffusion process starting from noise, Emu3 produces videos in a purely causal manner by autoregressively predicting the next token in a video sequence. The model can simulate some aspects of environments, people and animals in the physical world. Given a video in context, Emu3 extends the video and predicts what will happen next. On the basis of a user’s prompt, the model can generate high-fidelity videos following the text description. Emu3 stands out and competes with other video diffusion models for text-to-video (T2V) generation. In addition to standard generation, Emu3 supports interleaved vision–language generation and even vision–language–action modelling for robotic manipulation; this demonstrates the generality of the next-token framework.
We open-source key techniques and models to facilitate future research in this direction. Notably, we provide a robust vision tokenizer to enable transformation of videos and images into discrete tokens. We also investigate design choices through large-scale ablations, including tokenizer codebook size, initialization strategies, multimodal dropout, and loss weighting, providing comprehensive insights into the training dynamics of multimodal autoregressive models. We demonstrate the versatility of the next-token prediction framework, showing that direct preference optimization (DPO)13 can be seamlessly applied to autoregressive vision generation and aligning the model with human preferences.
Our results provide strong evidence that next-token prediction can serve as a powerful paradigm for multimodal models, scaling beyond language models and delivering strong performance across multimodal tasks. By simplifying complex model designs and focusing solely on tokens, it unlocks significant potential for scaling during both training and inference. We believe this work establishes next-token prediction as a robust and general framework for unified multimodal learning, opening the door to native multimodal assistants, world models and embodied artificial intelligence.
Emu3 architecture and training
We present a unified, decoder-only framework that models language, images and video as a single sequence of discrete tokens and is trained end-to-end with a next-token prediction objective. Figure 1 illustrates the framework. Our method comprises five tightly integrated components: (1) a large, mixed multimodal training dataset (see section 3.1 of the Supplementary Information); (2) a unified tokenizer that converts images and video clips into compact discrete token streams (‘Vision tokenizer’); (3) a transformer-based decoder-only architecture that extends an LLM’s embedding space to accept vision tokens while otherwise following standard decoder-only design choices (‘Architecture’); (4) a two-stage optimization recipe including large-scale multimodal pretraining with balanced cross-entropy loss and high-quality post-training to align with task formats and human preferences (‘Pretraining’ and ‘Post-training’); and (5) an efficient inference back end supporting classifier-free guidance (CFG), low latency and high throughput for autoregressive multimodal generation (‘Inference’).
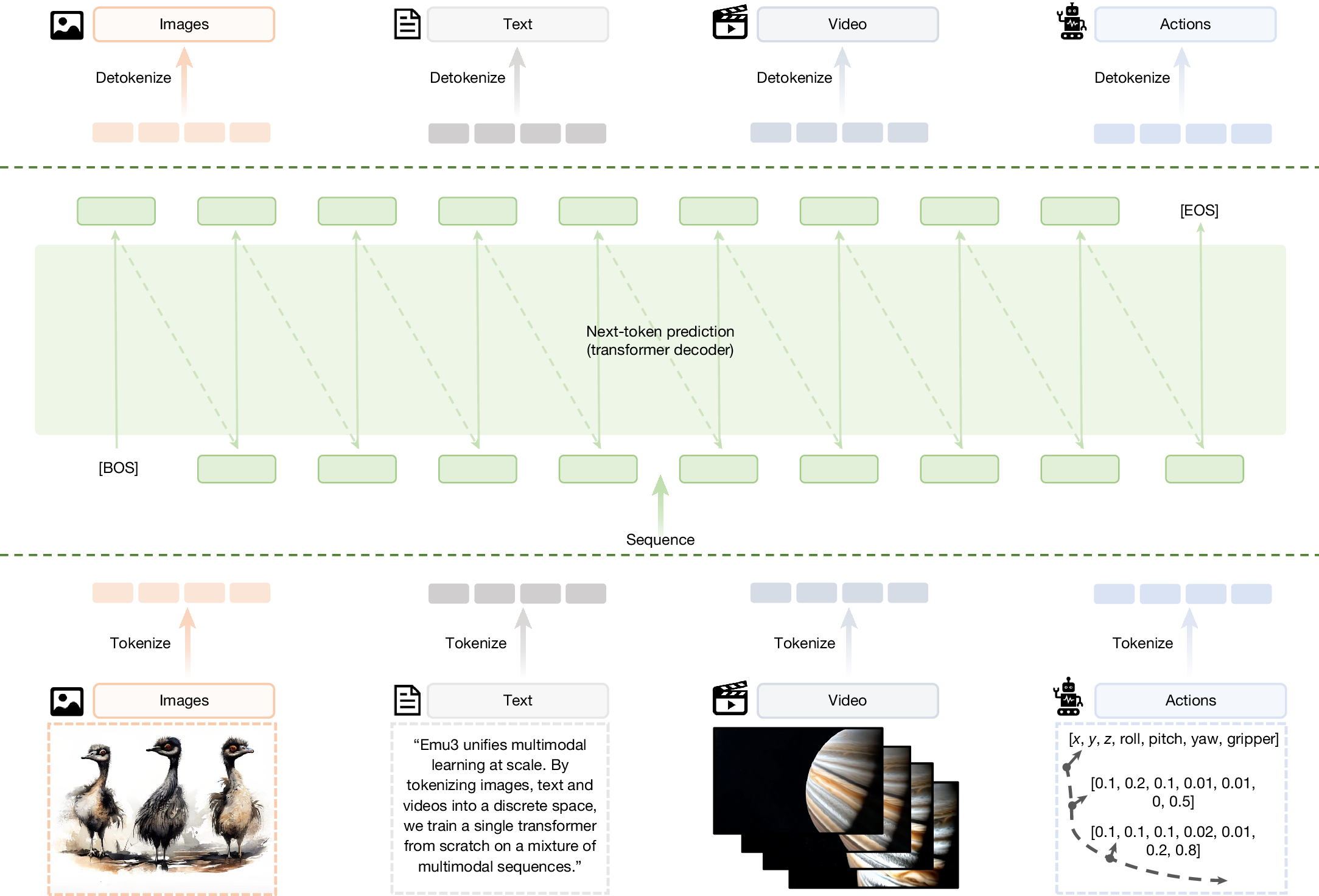
Emu3 first tokenizes multimodal data such as images, text, video and actions into discrete tokens and then sequences these tokens by order and performs unified next-token prediction at scale with a Transformer decoder. We have also seamlessly generalized the framework to robotic manipulation by treating vision, language and actions as unified token sequences.
Vision tokenizer
We trained a unified vision tokenizer that can encode a 4 × 512 × 512 video clip or a 512 × 512 image into 4,096 discrete tokens from a codebook of size 32,768. The tokenizer achieves 4× compression in the temporal dimension and 8 × 8 compression in the spatial dimension and is applicable to any temporal and spatial resolution. Building on the SBER-MoVQGAN architecture14, we incorporated two temporal residual layers with three-dimensional convolution kernels into both the encoder and decoder modules to perform temporal downsampling and enhance video tokenization capabilities.
Architecture
The Emu3 model retains the architectural framework of established LLMs such as Llama-2 (ref. 15), the primary modification being the expansion of the embedding layer to accommodate discrete vision tokens. A dropout rate of 0.1 was implemented to improve training stability. Methods section ‘Architecture design’ includes the architecture details and comparisons with architectural variants. We compared our approach with encoder-based vision–language architectures and diffusion baselines and found that a decoder-only token prediction architecture trained without any pretrained vision or language components could match traditional pipelines that rely on strong unimodal priors and thus offered a more unified, general-purpose design. This finding challenges the prevailing assumption that compositional or diffusion-based models are inherently superior for multimodal learning.
Pretraining
During pretraining, we first established a unified multimodal data format to allow Emu3 to process text, images and videos in a single autoregressive framework. In contrast to diffusion-based models that depend on at least one external text encoder, Emu3 accepts textual context into the model naturally and directly, enabling native joint modelling of multimodal data. All images and videos are resized with the aspect ratio preserved to a target scale. The visual contents are then converted into discrete vision tokens produced by our tokenizer. These tokens are combined with natural language captions and further metadata describing resolution, and, in the case of video, frame rate and duration. These components are interleaved using a small set of special tokens that delineate text segments, visual segments, and structural boundaries such as line and frame breaks. This yields a document-style sequence that standardizes heterogeneous multimodal inputs into a single token stream suitable for next-token prediction. We also included variants of the data in which captions appeared after the visual content rather than before it. This bidirectional arrangement encourages the model to learn both language-to-vision and vision-to-language mappings in a unified setting. As all information is fully tokenized, Emu3 can be trained end-to-end using a single next-token prediction objective with a standard cross-entropy loss. To maintain balanced learning across modalities, we slightly reduced the relative weight assigned to vision tokens so that a large number of visual tokens would not dominate optimization.
Emu3 uses an extensive context length during pretraining to handle video data. To facilitate training, we used a combination of tensor parallelism, context parallelism and data parallelism, simultaneously packing text–image data into the maximum context length to fully utilize computational resources while ensuring that complete images were not segmented during the packing process. Extended Data Table 1 details the training pipeline, including stage configurations, parallelism strategies, loss weights, optimization settings and training steps. The training computations are listed in Supplementary Table 7.
Post-training
Following the pretraining phase, we conducted post-training for vision generation tasks to enhance the quality of generated outputs. We applied quality fine-tuning (QFT) using high-quality data. The model continues training with the next-token prediction task using standard cross-entropy loss; however, supervision is applied exclusively to the vision tokens. During training, we increased the data resolution from 512 pixels to 720 pixels to improve generation quality. In addition, at the end of training, we used an annealing strategy to linearly decay the learning rate to zero. We adopted DPO13 to enable better alignment of models with human preferences. Human preference data were leveraged to enhance model performance for autoregressive multimodal generation tasks. The DPO model minimizes the DPO loss and the next-token prediction cross-entropy loss.
For vision–language understanding, the pretrained model underwent a two-stage post-training process: (1) image-to-text (I2T) training; and (2) visual instruction tuning. During the first stage, our approach integrates image-understanding data with pure-text data, and losses associated with vision tokens are disregarded for text-only prediction. Each image is resized to a resolution of about 512 × 512 while preserving the original aspect ratio. In the second stage, a subset of visual question answering data is sampled to enhance vision-instruction-following ability. Images with resolution less than 512 × 512 or greater than 1,024 × 1,024 are resized to the lower or upper resolution limit while keeping the aspect ratio, whereas all other images are retained at their original size. Figure 2 presents qualitative visualizations across diverse multimodal tasks.

Inference
Our multimodal inference framework inherits most of the key advantages of existing LLM infrastructures. It was built upon FlagScale16, a multimodal serving system developed on top of vLLM17. FlagScale extends the inference back end to support CFG18 for autoregressive multimodal generation. Specifically, we integrated CFG directly into the dynamic batching pipeline by jointly feeding conditional and negative prompts within each batch iteration. This CFG-aware extension introduces negligible overhead while maintaining the low-latency and high-throughput characteristics of vLLM.
Notably, we also present a vision for token-centric multimodal infrastructure in Fig. 3a; this is both efficient and extensible, demonstrating the practicality and scalability of our multimodal token prediction framework for large-scale real-world deployment. In this framework, data tokenization is performed directly on edge devices, and only the resulting discrete token IDs are transmitted to large-scale servers for unified multimodal training and inference. This approach greatly improves efficiency, as token IDs are substantially more compact than raw data such as images or videos.
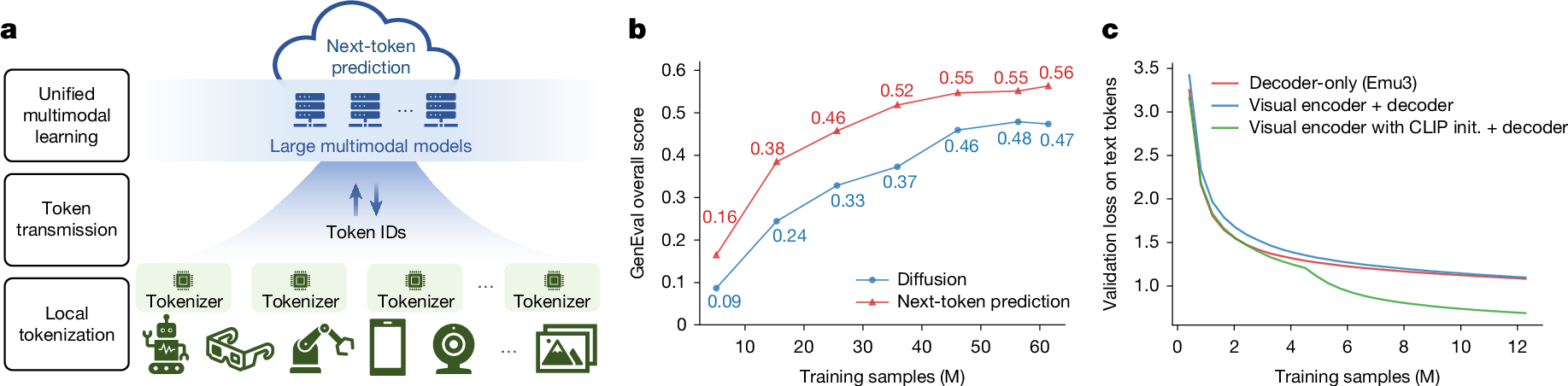
a, Multimodal data tokenization can be performed directly on edge devices, and only the resulting discrete token IDs are transmitted to large-scale servers for unified multimodal training and inference. b, GenEval overall scores as a function of training sample count for the image-generation task, comparing the latent diffusion and next-token prediction paradigms. c, Validation loss of text tokens as a function of training sample count for the image-understanding task, contrasting the decoder-only paradigm with the encoder + LLM compositional paradigm in the scenario in which the LLM is trained from scratch, with further comparisons according to whether CLIP initialization is applied. Init., initialization.
Evaluation
Main results
We identified consistent scaling laws as a core principle underlying unified multimodal learning at scale. Our analysis, which was inspired by the Chinchilla scaling law19, demonstrated that diverse tasks including T2I, I2T and T2V followed a shared scaling behaviour when the model was trained jointly in a unified next-token prediction framework. We used a power-law formulation to model the validation loss L(N, D) as a function of model size N and training data size D:
All tasks exhibited a consistent data scaling exponent β = 0.55. T2I and I2T shared a model scaling exponent α = 0.25, whereas T2V showed steeper scaling with α = 0.35. These results were supported by high-quality fits, with mean absolute percentage error below 3% and R2 values exceeding 0.99. Figure 4 summarizes the scaling behaviour of Emu3 across model size, dataset scale and predictive accuracy for the three multimodal tasks (T2I, I2T and T2V). The validation loss surfaces revealed clear power-law relationships as functions of training tokens and model parameters, exhibiting consistent trends across modalities. The predicted versus observed curves for the 7B model further validated the reliability of these scaling laws: extrapolations based solely on smaller models closely matched the measured 7B losses (R2 ≥ 0.95, mean absolute percentage error < 3%). Together, these results demonstrate that unified multimodal next-token training follows stable and predictable scaling dynamics, enabling accurate performance forecasting before full-scale training. These findings reinforce our central claim that a unified next-token prediction paradigm, when scaled appropriately, can serve as a simple yet powerful mechanism for multimodal learning, obviating the need for complex modality-specific fusion strategies.
The main results for image generation, vision–language understanding and video generation are summarized in Table 1, with well-established task-specific model series20,21,22 listed as references. We assessed the T2I generation capability of Emu3 through both human evaluation and automated metrics on several established benchmarks, including MSCOCO-30K23, GenEval24, T2I-CompBench25 and DPG-Bench26. As shown in Extended Data Table 2, Emu3 attained performance on par with that of state-of-the-art diffusion models. Supplementary Fig. 14 shows images generated by Emu3 to demonstrate its capabilities. Emu3 supports flexible resolutions and aspect ratios and is capable of handling various styles.
For video generation, Emu3 natively supports generation of 5-s videos at 24 fps and can be extended through an autoregressive approach. Supplementary Fig. 15 presents qualitative examples of video generation, with 6 frames extracted from the first 3 s. We quantitatively evaluated video generation performance with VBench toolkit27. As shown in Extended Data Table 3, Emu3 produced results highly competitive with those of other video diffusion models.
Emu3 can extend videos by predicting future frames. Figure 2 shows qualitative examples of video extension, with 2-s videos at 24 fps tokenized into discrete vision tokens as context. Emu3 predicts the subsequent 2 s of content in the same form of discrete vision tokens, which can be detokenized to generate future predicted videos. These examples demonstrate that use of only next-token prediction facilitates temporal extension of videos, including prediction of human and animal actions, interactions with the real world, and variations in three-dimensional animations. Furthermore, by extending the video duration in this manner, our approach is capable of iteratively generating videos that surpass its contextual length.
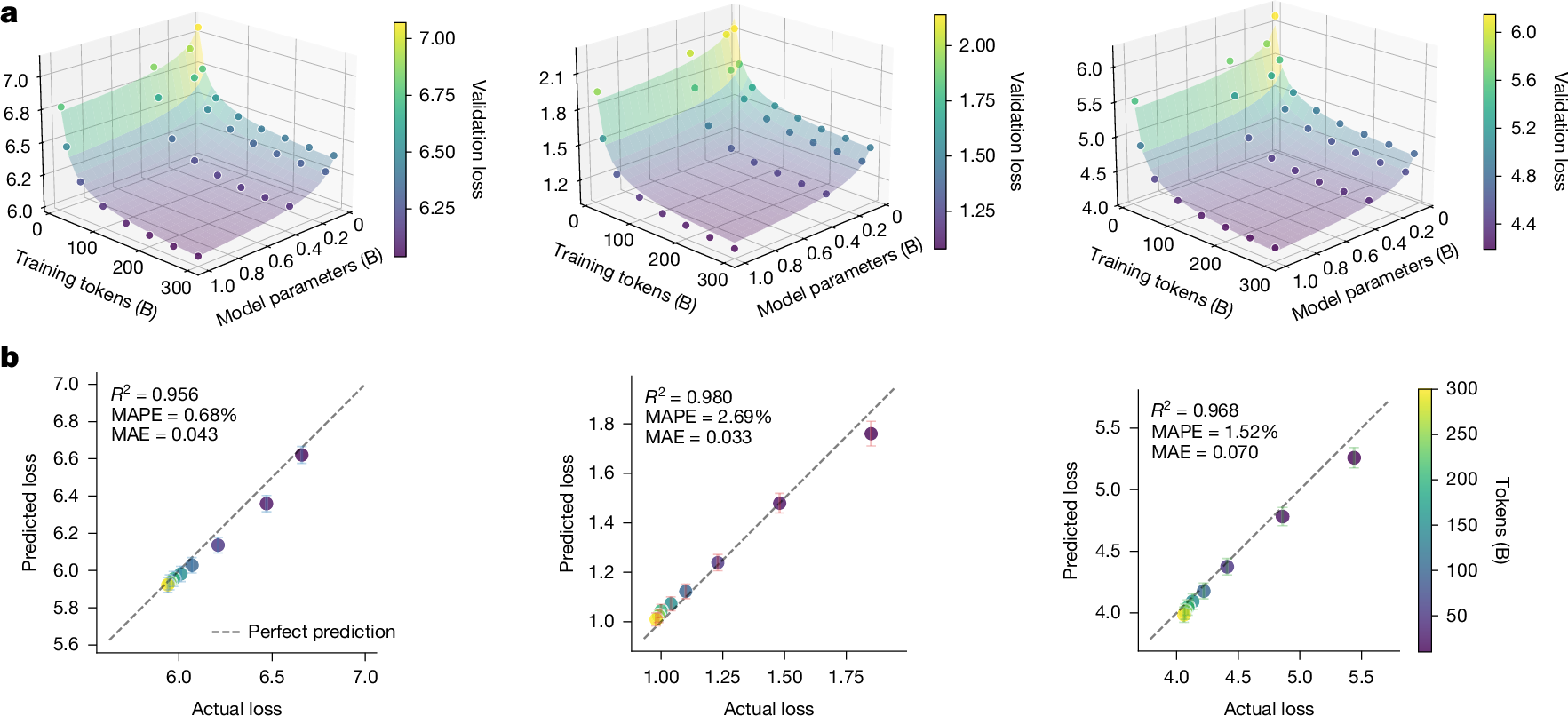
a, Validation loss surfaces for three tasks: T2I, I2T and T2V, shown as functions of model size and number of training tokens. All three tasks demonstrated clear power-law behaviour with respect to scale. b, Predicted versus observed validation loss using the fitted scaling laws for the 7B Emu3 model on T2I, I2T and T2V tasks. The predictions were closely aligned with measured performance, which validated the extrapolation capability of the learned scaling relationships. MAE, mean absolute error; MAPE, mean absolute percentage error.
To evaluate the vision–language understanding capabilities of our approach, we tested it across various public vision–language benchmarks. The primary results, detailed in Extended Data Table